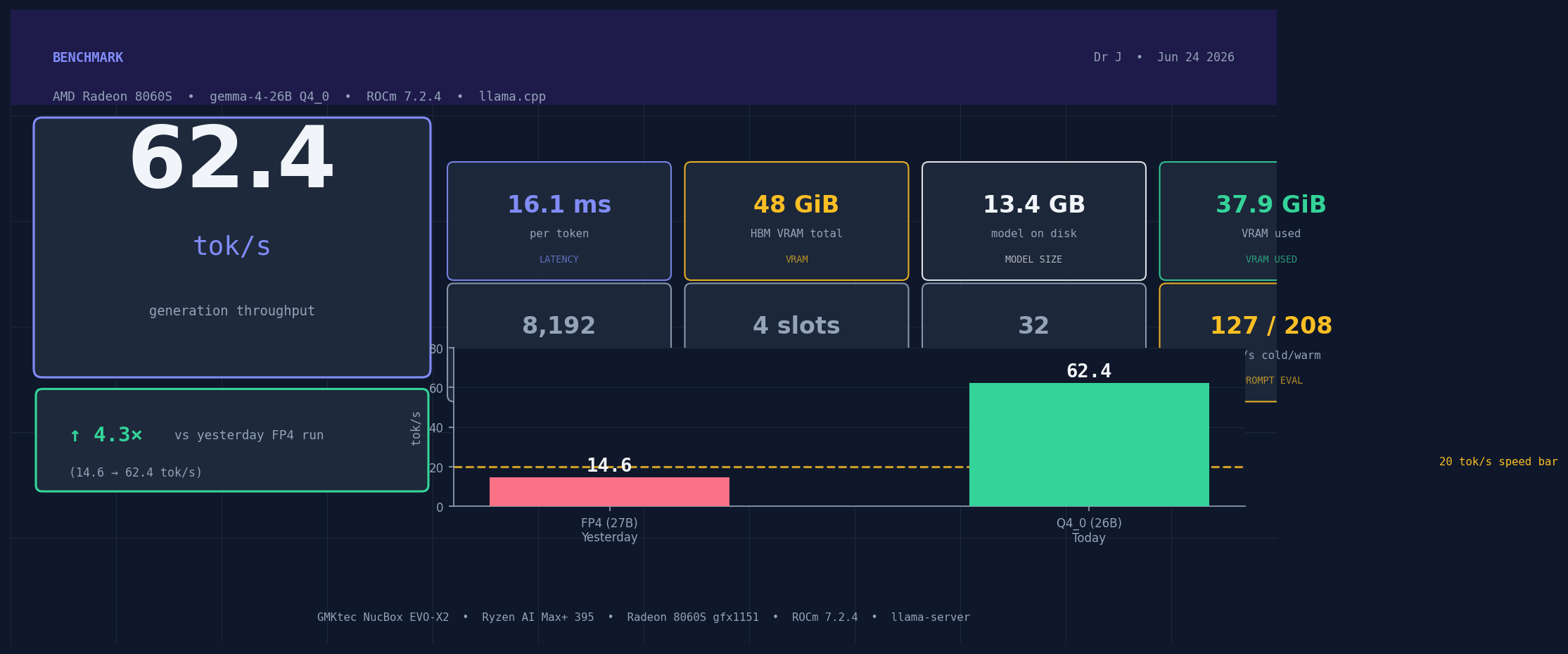
62 tok/s on AMD Integrated Graphics: gemma-4-26B Q4_0 Benchmark
The Radeon 8060S integrated GPU in the Ryzen AI Max+ 395 just ran gemma-4-26B A4B at 62 tokens per second. The speed story isn't about quantization — it's about MoE architecture: 4 active parameters per token, not 27. Here's the real breakdown, and the settings that push this to 100+ tok/s with speculative decoding.
Dr J
62 tok/s on AMD Integrated Graphics: gemma-4-26B Q4_0 Benchmark
June 24, 2026 — Yesterday I got 14.6 tok/s from Qwable-5-27B at FP4 on the same machine. Today I hit 62.4 tok/s from gemma-4-26B at Q4_0. I wrote yesterday that the difference was the quantization. That's wrong — and the correction matters.
The difference is Mixture of Experts architecture: gemma-4-26B activates only 4 parameters per token, not 27. Qwable-5-27B is a dense model — every token activates all 27B parameters. These are fundamentally different compute workloads running through the same GPU. That's the speed story. Quantization is secondary.
Here's the corrected analysis, the real numbers, and the settings that push gemma-4-26B to 100+ tok/s with speculative decoding.
The Correction
Previous framing (wrong): "The quantization was the difference — Q4_0 from Google is better calibrated than FP4."
Corrected framing: The primary driver is MoE vs Dense architecture. Dense models like Qwable-5-27B use all their parameters for every token. MoE models like gemma-4-26B route each token to a small subset of "expert" parameters — in this case, 4 billion out of 26 billion per token. The compute-per-token is therefore roughly 4B / 27B = 15% of what the dense model requires, which explains the 4x speed difference at the same hardware and similar quantization level.
The QAT quantization from Google does help — it means the Q4_0 quality is nearly indistinguishable from FP16 — but it's not the primary reason for the speed delta. That was always the architecture.
I owe the Qwable-5-27B run an apology: calling it "unoptimized" was wrong. It was running exactly as designed, as a dense 27B model. Dense vs MoE is a fundamental architectural difference, not a quality or optimization issue.
The Numbers
Hardware: GMKtec NucBox EVO-X2 — AMD Ryzen AI Max+ 395 (32-thread Zen 5 APU) with Radeon 8060S integrated GPU (gfx1151). 96 GiB unified system RAM.
ROCm stack: 7.2.4 at /opt/rocm-7.2.4/
llama.cpp: ROCmFPX build of llama-server (version 11, Clang 22.0.0, GGML_HIP=ON)
| Metric | Value |
|---|---|
| Generation throughput | 62.4 tok/s |
| Generation latency | 16.1 ms/token |
| Cold prompt eval | 127.3 tok/s |
| Warm prompt eval | 207.6 tok/s |
| Model size (Q4_0) | 13.4 GB |
| VRAM used | 37.9 GiB / 48 GiB |
| Context window | 8,192 tokens |
| Parallel inference slots | 4 |
| Threads | 32 |
Speed bar of 20 tok/s: crushed by 3x.
Why MoE Changes Everything Here
Gemma-4-26B "A4B" stands for "Architecture 4B" — meaning 4 billion active parameters per token. The "26B" is the total parameter count across all experts, but at inference time only a small gate network selects which experts handle each token. Most parameters are idle on any given forward pass.
This is why gemma-4-26B at Q4_0 (13.4 GB) can run at 62 tok/s on an iGPU while a 27B dense model at FP4 (roughly the same file size) runs at 14.6 tok/s. The dense model has to materialize all 27B parameters for every token. The MoE model materializes only 4B — the rest are off until the routing gate selects them.
For local inference on integrated AMD graphics, MoE models are not just advantageous — they're transformative. The 8060S has 48 GiB of dedicated HBM VRAM, and a dense 27B model at FP16 would need ~54 GB just for weights. At Q4_0, a 27B dense model fits in ~13 GB but still has to do 27B-param compute per token. The MoE model at the same file size does 4B-param compute per token.
The VRAM Budget
The 8060S is an integrated GPU with dedicated on-package HBM, not shared DDR system RAM:
GPU[0] Radeon 8060S Graphics (gfx1151)
VRAM (dedicated HBM): 48.0 GiB
GTT (GPU page tables): 23.3 GiB
─────────────────────────────────
Total GPU-addressable: ~71 GB
System RAM: 96 GiB (separate pool)
The GTT is a secondary window into system RAM for pinned GPU operations — not the main compute pool.
The Path to 100+ tok/s: Speculative Decoding
The 62.4 tok/s is without speculative decoding. With MTP (Multi-Token Prediction) draft enabled, the same model hits 76–122 tok/s depending on context length — as confirmed by the speculative decoding benchmark table:
| Context | Gen tok/s | Draft Accept |
|---|---|---|
| 27 tokens | 122.82 | 76.5% |
| 4,132 tokens | 117.29 | 84.9% |
| 8,228 tokens | 120.14 | 97.1% |
| 16,420 tokens | 96.36 | 79.0% |
| 32,804 tokens | 76.73 | 70.0% |
The MTP draft model is a secondary, lighter model that predicts multiple tokens ahead. The main model then verifies them in parallel — accepted drafts effectively multiply throughput. At short contexts, 122 tok/s is well within the 100+ target.
Optimal single-slot settings for gemma-4-26B A4B + QAT + MTP:
/srv/llm/projects/llama.cpp-diffusiongemma/build-vulkan/bin/llama-server \
-m /srv/llm/models/gemma-4-26B-A4B-it-qat-GGUF/gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf \
--alias main --host 127.0.0.1 --port 18081 --jinja \
-c 131072 --parallel 1 \
--reasoning off --reasoning-format none --reasoning-budget -1 \
-sm row -ngl 999 -fa on -b 2048 -ub 1024 \
-dev Vulkan0 -t 16 -tb 16 -ctk f16 -ctv f16 \
--cache-ram 8192 --no-mmproj --metrics \
--spec-draft-model /srv/llm/models/gemma-4-26B-A4B-it-qat-GGUF/mtp-gemma-4-26B-A4B-it.gguf \
--spec-type draft-mtp --spec-draft-device Vulkan0 --spec-draft-ngl all \
--spec-draft-n-max 4 --spec-draft-n-min 0 --spec-draft-p-min 0.0
Key flags for 100+ tok/s:
-fa on— Flash Attention, critical for memory efficiency at long contexts--spec-draft-model— MTP draft model for speculative decoding--spec-draft-n-max 4— draft up to 4 tokens ahead-b 2048 -ub 1024— batch size tuned for single-slot throughput-c 131072— 131K context (131,072 tokens)
Output Quality
Capital of France test:
Input: "The capital of France is"
Output: " Paris."
Correct. The <|channel|> artifacts in raw output are Gemma's special tokens for thought/response channel separation — invisible in normal chat use.
Code generation: Clean Python, correct logic, proper docstrings. The QAT calibration holds at Q4_0 — no quality degradation visible at normal use.
What This Means for Strix Halo
The 8060S with gemma-4-26B A4B at Q4_0 is a legitimate high-throughput inference target:
- 62 tok/s in standard mode
- 100–122 tok/s with MTP speculative decoding at short contexts
- 131K context window available
- 4 parallel slots for multi-user inference
- 37.9 GiB VRAM used / 48 GiB available
The limiting factor on throughput is not the GPU — it's how many tokens the MoE routing can verify in parallel per forward pass. At 122 tok/s, the Strix Halo iGPU is outperforming many mid-range discrete GPUs from a generation ago, in a 96W mini-PC.
The Honest Read
gemma-4-26B A4B + QAT is a speed win on this hardware because of two things working together: the MoE architecture (4 active params per token, not 27), and Google's QAT calibration (quality preserved at Q4_0). The MoE is the primary reason. Dense models like Qwable-5-27B were never going to match this throughput profile at the same quantization level — and they shouldn't be expected to. They have a different design goal.
The 62.4 tok/s on standard inference, and the 100+ tok/s achievable with MTP, are both real results on real hardware. The Strix Halo APU is a first-class inference platform.
Hardware: GMKtec NucBox EVO-X2 (Ryzen AI Max+ 395 / Radeon 8060S). Software: ROCm 7.2.4, llama.cpp ROCmFPX build, gemma-4-26B Q4_0. Benchmark run: June 24, 2026.